The Oracle of ChatGPT and Why We Need to Think More Critically About Generative AI
In the past year, ChatGPT and other generative AI tools have increasingly dominated media headlines and public discourse, establishing themselves as defining technologies of our time. However, like many new technologies, ChatGPT has limitations. So far these limitations have largely been overshadowed by the technology’s exciting potential and general hype surrounding generative AI [1]. Many users remain unaware of the subtle ways in which engaging with tools like ChatGPT may shift their perspective or reinforce certain biases. As user numbers continue to climb, we must think critically about the tool’s biases and mitigate their impact, particularly for vulnerable users such as children.
To those less familiar with the technology, ChatGPT is a generative artificial intelligence tool, which creates human-like text content in response to a prompt. To understand ChatGPT’s capacity for bias, it’s helpful to consider the models behind this tool, known as large language models. A large language model (LLM) can be thought of as a system that uses statistical learning to predict text based on large amounts of training data. These models are fed data from several sources, such as internet pages and books, which help them learn the structure of human language. Like a student learning from an outdated textbook, these models absorb biases that are present in their training data.
LLMs are technically complex and understanding their functionality is perhaps less important than harbouring awareness of their ongoing limitations, including the potential to perpetuate bias and misinformation. Gender bias has been widely reported in the ChatGPT’s output, the likes of which are best understood through examples. When I asked ChatGPT to tell me a story about a girl and boy at school, I received a story about Alex, who had “incredible aptitude in mathematics”, and Emma, who had a talent for literature and “often sought Alex's help with her assignments”. Other languages produced similar narratives: in German, Maria was responsible for the baking, Otto oversaw the finances; in French, Andre was an engineer who wooed Claire the biologist. Comparable stereotypes have been cited across research studies[2], with ChatGPT often promoting outdated notions (boys become doctors, girls become teachers) rather than neutral representations[3]. More obvious biases have emerged when ChatGPT has been asked to make clinical assessments, including the tendency to rank cardiac stress tests as more important for male than female patients, even when they present with identical symptoms[4]. This issue of gender bias has led some researchers to develop algorithms that explicitly quantify the extent to which these models contain biases in their output (the results for common models like GPT 4 are damning)[5].
To users aware of ChatGPT’s limitations, these stereotype effects may seem benign; side effects that accompany the uptake of unpredictable new technologies. However, there exists a very real use case of people who frequently use ChatGPT and accept its output without a critical lens. Consider, for example, a student needing to submit a creative story for a high school English paper or an intern pulling stats for a team presentation. In both these cases, ChatGPT’s seamless answers may well be adopted without a second thought. At the individual level, these cases may again seem harmless, but if hundreds of thousands of students are using biased AI tools to help formulate arguments or develop new ideas (and the penetration rate of ChatGPT appears to be at least this deep[6]) then the capacity for biased AI tools to increase human biases becomes alarmingly real (see Figure 1)[8]. From an ethical standpoint, this creates an interesting moral quagmire; if learning from biased AI tools increases users’ knowledge while simultaneously increasing future errors, is the tool worth using? Practically, this biased feedback loop requires researchers, educators and technologists to consider how we can best train the next generation of technology users to critically appraise these tools.
Figure 1. The Biased Feedback Loop of Generative AI[7]
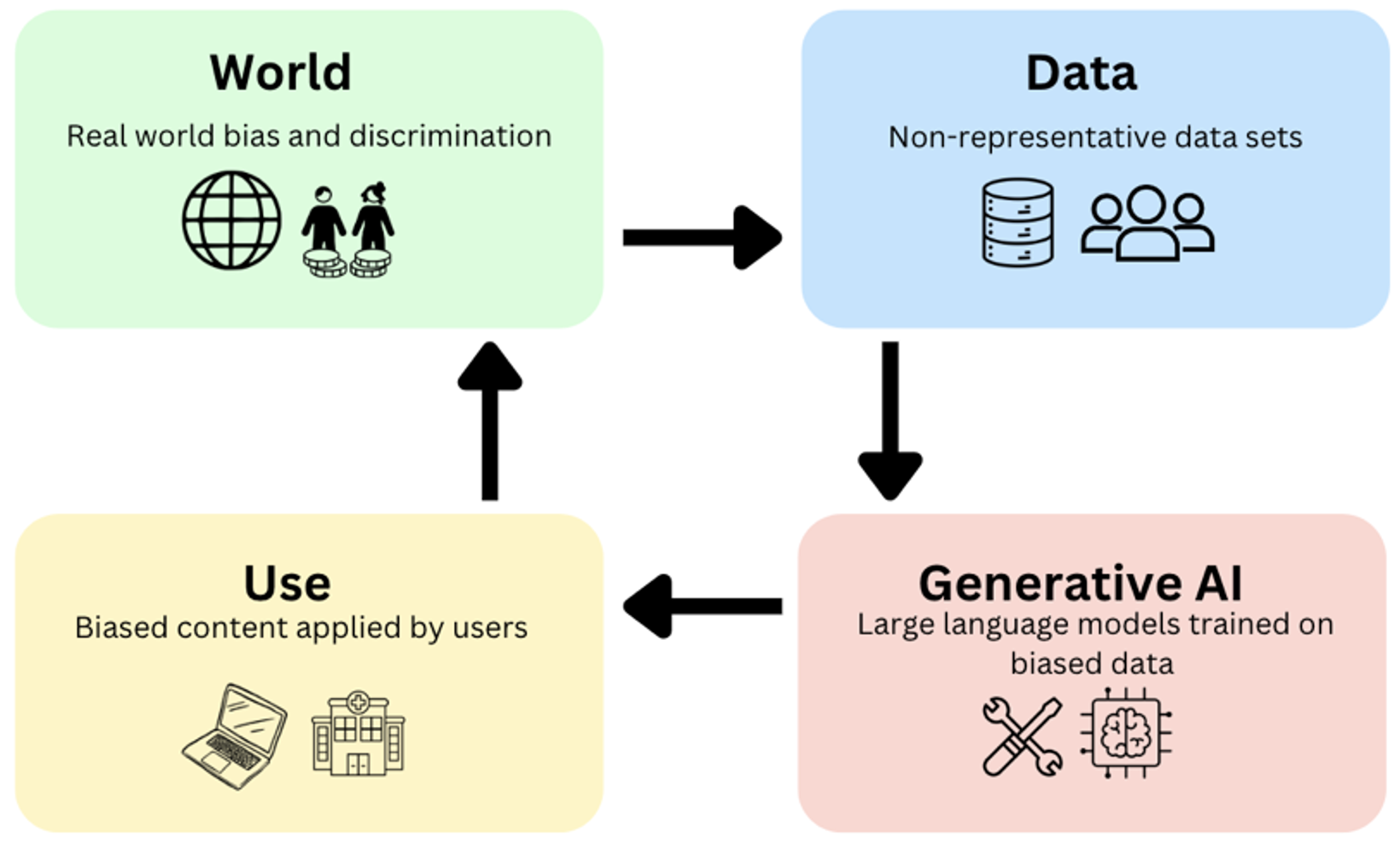
A related concern is ChatGPT’s (and other genAI tools) tendency to ‘hallucinate’ or make up false information. Unlike some chatbots, ChatGPT does not openly cite the sources of its information, making it a potent agent for misinformation if users do not verify its output. Our willingness to accept ChatGPT as a credible source is compounded by the tool’s uncontested capacity for awe. ChatGPT can quickly translate texts, fix code and produce entire essays from scratch, astonishing features that likely diminish our ability to consider any of the tool’s shortcomings (known in psychology as the halo effect). If we were to anthropomorphise ChatGPT (for argument’s sake) we would have a seemingly intelligent person who can quickly provide answers to many questions across many subjects. However, this person would not tell you how they know these things, confidently make-up information, and have an inclination to pigeonhole half of the population as nurses and teachers. In short, this person is not someone most people would trust.
So where do we go from here? As the number of ChatGPT users continues to rise, the need for appropriate guardrails feels urgent. On the technical front, progress to fix biases in generative AI is being made. Both ChatGPT and GPT-4 have options for user feedback that, when applied in the right way, could reduce the amount of bias and false information they produce. The same organisations measuring biases in LLMs are also building tools like EquitAI, which can be added to models like ChatGPT to mitigate biased text output[12]. Scientists are also calling for independent regulatory bodies as well as processes that see AI models vetted before they are released to the public[13]. More broadly, public usage of these tools should be accompanied by education about their inherent limitations, especially for young people, who may be less cognisant of these biases and more vulnerable to their influence.
When it comes to imagining the future use of tools like ChatGPT, it may be helpful to think of the Wikipedia analogy. Wikipedia is a widely used source of information, helpful for reading information on almost any subject. However, almost every student is told at some point in their education not to blindly trust Wikipedia; its content is subject to bias and manipulation. While generative AI functions differently from Wikipedia, it may be helpful to engage a similarly critical lens when using these tools, which, despite their capacity for awe, are not oracles but evolving technologies with important limitations.
References
[1] Ghosh and Caliskan, “ChatGPT Perpetuates Gender Bias in Machine Translation and Ignores Non-Gendered Pronouns.”
[2] Singh, S. (2023). Is ChatGPT Biased? A Review.
[3] https://twitter.com/IvanaBartoletti/status/1637401609079488512
[4] Coding Inequity: Assessing GPT-4’s Potential for Perpetuating Racial and Gender Biases in Healthcare
Travis Zack, Eric Lehman, Mirac Suzgun, Jorge A. Rodriguez, Leo Anthony Celi, Judy Gichoya, Dan Jurafsky, Peter Szolovits, David W. Bates, Raja-Elie E. Abdulnour, Atul J. Butte, Emily Alsentzer
medRxiv 2023.07.13.23292577; doi: https://doi.org/10.1101/2023.07.13.23292577
[5] https://buildaligned.ai/blog/using-faair-to-measure-gender-bias-in-llms
[6] https://www.bbc.co.uk/news/education-67236732
[7] https://www.bmj.com/content/372/bmj.n304
[8] https://www.nature.com/articles/s41598-023-42384-8
[9] https://www.flexjobs.com/blog/post/the-ai-gender-gap-exploring-variances-in-workplace-adoption
[10]https://www.bbc.co.uk/news/business-67217915
[11] https://www.forbes.com/sites/mollybohannon/2023/06/08/lawyer-used-chatgpt-in-court-and-cited-fake-cases-a-judge-is-considering-sanctions/
[12] https://buildaligned.ai/blog/using-faair-to-measure-gender-bias-in-llms
[13] Bockting et al., “Living Guidelines for Generative AI — Why Scientists Must Oversee Its Use.”